1.为什么需要分词组件?
中文分词 (Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂的多、困难的多。
中文分词是信息提取、信息检索、机器翻译、文本分类、自动文摘、语音识别、文本语音转换、自然语言理解等中文信息处理领域的基础研究课题。对于中文分词的研究对于这些方面的发展有着至关重要的作用。可以这样说,只要是与中文理解相关的领域,都是需要用到中文分词技术的。
在信息抽取的实际应用中,我们除了面对HTML这种带有标签分隔的数据外,还面临着一些没有任何标签的纯文本内容识别。如何从纯文本中抽取出我们感兴趣的内容就需要用到中文分词技术。如以下的一段文本:
2006-2-9 1:12 城区文昌路火车站对面,十分前,张*文被两名男子驾驶男装,牌照为粤A3***21摩托车飞车抢走一台手机和钱包一个,号码:136****5300,现金约600元,身份证一张:51031519760****77117两名行为人其中一个穿黑色衣服,留长发,得手后往乐安方向逃跑,其它不详。 通报路面巡警交警注意发现. 通知*山辖区巡警(469)前往处理,复地址清楚。 通报*海110(3926号)协查. 通报路面警力注意发现。
我们可以通过抽取组件和分词组件结构化抽取出以下的内容:
| 字段 | 值 |
|---|---|
| 发案日期 | 2006-2-9 1:12 |
| 发案地市 | *山 |
| 发案地段 | 城区文昌路火车站对面 |
| 涉案人员 | 张*文 |
| 车牌号码 | A3***21 |
| 手机号码 | 136****5300 |
| 案件关键字 | 摩托车飞车、抢走、逃跑 |
| 身份证号码 | 51031519760****77117 |
| 现金金额 | 约600 |
通过对大量的类似数据的结构化与抽取后,我们就可以将原来的文本数据变得可以分析、可统计、可检索、可计算相似度等运算,以便于给大数据插上腾飞的翅膀,并为数据拥有者提供更大价值的综合利用。
2.瞬速分词组件的特色功能
Ⅰ 网络上已有很多的分组组件,但是这些分组件大多是面向于通用地中文文本信息的处理。而瞬速的分组组件首要的目的是为了信息的抽取而产生的。由于面对的信息完全可能是不规范的,比如不该换行的作了换行;中间有HTML转义符等都可能导致分词无效。我们的分词组件首先解决地是这种可能中间包含有噪声串的信息。通过对网页信息进行规范化后,根据抽取的业务需求,通过预制的分词扩展规则插件扩展对通用分词组件进行扩散。如通用的组件在识别人名需要人名比较规范如张三、李四。而网页上的信息往往是昵称、化名或如某某之类的。瞬速分词组件可以很灵活地为抽取而扩展不同的插件。
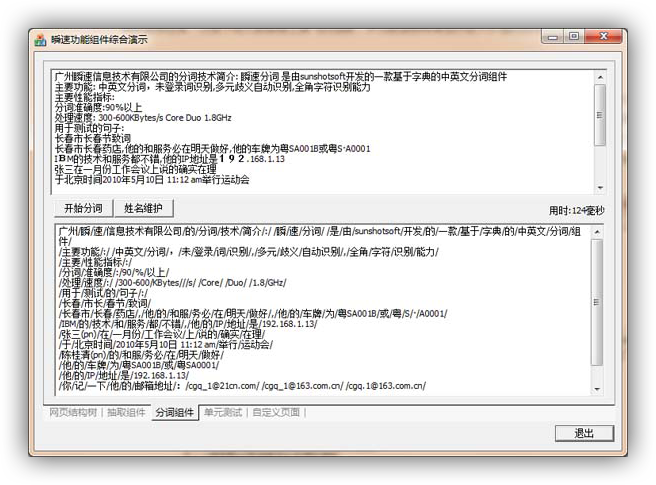
中文分组组件测试效果
Ⅱ 瞬速分词组件除了具备有通用分词组件的中文切词、歧义解决之外。还可以解决中英文合词的识别,其它的通用分词则只能地纯中文或纯英文的分词。但是在而向抽取业务的需求中,如需要从文本中抽取车牌号、地址、昵称等信息中包含有中英文混合的词语,则需要分词组件具备有这种中英文混合词的识别与切词。为了满足简单的抽取配置,瞬速分词引了智能标签参与分词,如需要从网页中抽取出如信息“房型:三房二厅”或如“房屋类型:三房两厅”,按通用的分词组件可能被分成了“房型/:/三房/二厅”,然而瞬速分词组件是因抽取而生,则分词成了“房型/:/三房二厅/”,从而可以将分词结果直接应用于抽取结果。

瞬速分词在数据抽取与挖掘中的应用
3.性能参数列表
| 序号 | 组件功能 | 支持 |
|---|---|---|
| 01 | 支持中文未登录词识别 | √ |
| 02 | 可以根据词频来解决分词的歧义问题 | √ |
| 03 | 支持根据抽取业务的需求解决歧义问题 | √ |
| 04 | 支持中文简体和繁体并行分词 | √ |
| 05 | 支持词性和词语位置为抽取而准备 | √ |
| 06 | 支持抽取常用的网络词语如QQ号、邮箱、昵称等 | √ |
| 07 | 支持在分词时对时间的统一化(如2013/01/01、2013年07月01) | √ |
| 08 | 支持通过正则表达式对分词进行批快速切词 | √ |
| 09 | 支持在分词时按智能标签形式的内容进行整体抽取(如“房型:三房二厅“) | √ |
| 10 | 支持通过脚本文件对文本进行分词扩展 | √ |
| 11 | 支持中英文合词输出,如车牌号、门牌号等以便形成完整的抽取信息 | √ |
4.分组组件应用展示

企业文档检索系统

互联网舆情监测系统
5.技术文献参考列表
| 01.中文分词技术的研究现状与困难 |
| 中文分词技术是中文信息处理领域的基础研究课题。而分词对于中文信息处理的诸多领域都是一个非常重要的基本组成部分。首先对中文分词的基本概念与应用 , 以及中文分词的基本方法进行了概述。然后分析了分词中存在的两个最大困难。最后指出了中文分词未来的研究方向。 |
| 02.基于Lucene的中文分词方法设计与实现 |
| 本文设计实现了一个中文分词模块,其主要研究目的在于寻找更为有效的中文词汇处理方法,提高全文检索系统的中文处理能力。整个模块基于当前最流行的搜索引擎架构Lucene,实现了带有歧义消除功能的正向最大匹配算法.在系统评测方面,比较了该方法与现有方法的区别,对于如何构建一个高效的中文检索系统,提出了一种实现。 |
| 03.Nutch中文分词的设计与实现 |
| 面对与日俱增的中文信息检索需求,Nutch作为一个开源的搜索引擎系统平台受到众多开发者的青睐,但由于Nuch是基于英文的系统,不具备中文分词能力,因此,研究中文分词方法在Nutch中的应用对实现中文搜索引擎具有非常现实的意义,在对中文分词技术进行研究的基础上,设计并实现了具有中文分词功能和新词识别功能的分词器。在Nutch中实现了中文分词功能,实验测试结果表明,算法的分词效果能够达到预期的中文分词的要求。 |
| 04.基于词典的中文分词歧义算法研究 |
| 本文采用了一种典型的基于词典的中文分词算法--正向量大匹配算法,它的思想简单,并且易于实现,但是分词的精确度和速度并不理想。针对该问题,本文采用了双层HASH结构的词典机制,来提升分词的速度,同时采用改进的正向最大匹配算法来提高分词的精确度。其次,由于歧义处理技术是中文分词技术中的重要组成部分,只有完成了对文本的歧义处理,才能正确的对文本进行分词。所以本文在提出改进的正向最大匹配算法的基础上,又提出一种基于概率和规则相结合的歧义消解算法,完成了对文本的歧义处理。 |
| 05.一种基于规则的中文分词算法 |
| 本文提出了一种基于词库的结合词频、词性、中文文法规则和未登词识别规则的分词算法,该算法首先通过采用基于词库的跨度为1的前向最大匹配分词算法获得初步的分词结果,然后依据中文文法规则和词条筛选规则对初步结果进行再次划分,得到优化的分词结果,最后通过未登词识虽规则对分词结果进行检查,将满足未登录条件的新词加入词库。该分词算法能够在很大程度上消除歧义划分,提高未登录词的识别概率。实验结果表明,该分词算法的准确率能达到97%以上,在效率上也具有很大优势。 |
| 06.面向信息检索的自适应中文分词系统 |
| 新词的识别和歧义的消解是影响信息检索系统准确度的重要因素,提出一种基于统计模型的,面向信息检索的自适应中文分词算法,基于此算法,设计和实现了一个全新的分词系统,它能够识别任意领域的各类新词,也能进行歧义消解和切分任意合理长度的词,它采用迭代二元切分方法,对目标文档进行在线词频统计,使用离线词频词典或搜索引擎的倒排索引,筛选侯选词并进行歧义消解。在统计模型的基出上,采用姓氏列表、量词表以及停词列表进行后处理,进一步提高了准确度。 |
| 07.基于哈希算法的中文分词算法的改进 |
| 中文分词是中文信息处理一个重要的部分,一些应用不仅要准确率,速度也很重要,通过对已有算法的分析,特别是对快速分词算法的分析,提出一种新的词典结构,并根据新的词典给出新的分词算法,该算法不仅对词首字实现了哈希查找,对词余下的字也实现哈希查找。理论分析和实验结果表明,算法在速度和效率比现有的几种分词算法上有所提高。 |
| 08.基于中文分词技术的信息智能过滤系统 |
| 讨论了中文信息的智能过滤问题,综合考虑了系统的准确性和智能性,将中文分词技术和贝叶斯推理相结合,并针对目前不良信息的特点,改进了中文分词算法。实验证明此系统对不良信息的智能识别具有很高的准确性。 |
| 09.基于有效子串标注的中文分词 |
| 由于基于已切分语料的学习方法和体系的兴起,中文分词在本世纪的头几年取得了显著的突破。尤其是2003年国际中文分词评测活动Bakeoff开展以来,基于字标注的统计学习方法引起了广泛关注。本文探讨这一学习框架的推广问题,以一种更为可靠的算法寻找更长的标注单元来实现中文分词的大规模语料学习,同时改进已有工作的不足。我们提出子串标注的一般化框架,包括两个步骤,一是确定有效子串词典的迭代最大匹配过滤算法,二是在给定文本上实现子串单元识别的双词典最大匹配算法。该方法的有效性在Bakeoff-2005评测语料上获得了验证。 |

-
地址: 广州市天河区员村四横路石东商务中心918
-
电话: 020-2903 9615
-
手机: 13533909695
-
QQ: 747484429
-
邮箱: 747484429@qq.com

