不少朋友看了沙漠君的文章后,都会问:那几十万条租房,二手房,薪酬,乃至天气数据都是从哪里来的?其实我还没告诉你这些数据在十几分钟内就可以采集到!一般我会回答,我用专门的工具,无需编程也能快速抓取。之后肯定又会被问,在哪里能下载这个工具呢?
这篇文章介绍爬虫大概的原理,文末会有程序地址。什么是爬虫?互联网是一张大网,采集数据的小程序可以形象地称之为爬虫或者蜘蛛。爬虫的原理很简单,我们在访问网页时,会点击翻页按钮和超链接,浏览器会帮我们请求所有的资源和图片。所以,你可以设计一个程序,能够模拟人在浏览器上的操作,让网站误认为爬虫是正常访问者,它就会把所需的数据乖乖送回来。爬虫分为两种,一种像百度那样什么都抓的搜索引擎爬虫。另一种就是《瞬速网络信息采集系统》,只精确地抓取所需的内容:比如我只要二手房信息,旁边的广告和新闻一律不要。 基本不需编程,通过便捷的选择来快速设计爬虫。它能在5分钟内编写完大众点评的爬虫,然后让它运行就好啦。
自动将网页导出为Excel那么,一个页面那么大,爬虫怎么知道我想要什么呢?
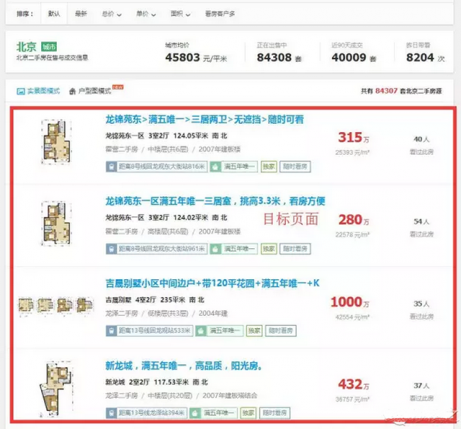
人当然可以很容易地看出,上图的红框是二手房信息,但机器不知道。网页是一种有结构的树,而重要信息所在的节点,往往枝繁叶茂。 举个不恰当的比方,一大家子人构成树状族谱,谁最厉害?当然是:
- 孩子多,最好一生20个
- 孩子各个都很争气(生的孙子多)
- 最好每个孩子还都很像(清一色的一米八)
- 大家就会觉得这一家子太厉害了!
我们对整个树结构进行打分,自然就能找到那个最牛的节点,就是我们要的表格。找到最牛爸爸之后,儿子们虽然相似:个子高,长得帅,两条胳膊两条腿,但这些都是共性,没有信息量,我们关心的是特性。大儿子锥子脸,跟其他人都不一样,那脸蛋就是重要信息;三儿子最有钱——钱也是我们关心的。 因此,对比儿子们的不同属性,我们就能知道哪些信息是重要的了。回到网页采集这个例子,通过一套有趣的算法,给一个网页的地址,软件就会自动地把它转成Excel!
破解翻页限制获取了一页的数据,这还不够,我们要获取所有页面的数据!这简单,我们让程序依次地请求第1页,第2页...数据就收集回来了就这么简单吗?网站怎么可能让自己宝贵的数据被这么轻松地抓走呢?所以它只能翻到第50页或第100页。链家就是这样:

这也难不倒我们,每页有30个数据,100页最多能呈现3000条数据。北京有16个区县两万个小区,但每个区的小区数量就没有3000个了,我们可分别获取每个区的小区列表。每个小区最多有300多套在售二手房,这样就能获取链家的所有二手房了。哈哈哈,是不是被沙漠君的机智所倾倒了?然后我们启动抓取器,Hawk就会给每个子线程(可以理解为机器人)分配任务:给我抓取这个小区的所有二手房! 然后你就会看到壮观的场面:一堆小机器人,同心协力地从网站上搬数据,超牛迅雷有没有?同时100个任务!!